(Fiber架构系列时隔1年半的更新😂,真的是这段时间太忙了)
本文介绍的是React的架构设计中,和性能优化有关的知识点的原理。包括Diff算法、bailout策略、与Vue的对比等。干货很多,阅读时间很长,而且不太容易消化。最好在阅读本文的同时结合源代码一起食用。如果实在没有时间和耐心阅读的,可以直接看我每一节的总结。
前言
我们都知道,React在触发更新后,不管是哪个方法触发的更新,都会从rootFiber(代码)发起一次异步调度的更新或者同步更新。当执行渲染时,也是从rootFiber节点开始,遍历整颗树来执行协调(render阶段)和提交DOM变更(commit阶段)。可能有的同学就会问了,假如我的fiber树结构很复杂,如果某次更新仅仅只有一个后代节点的某文字发生变化。这么小的变动如果还需要这么大费周章,那这个性能是不是太差了?
为什么React总是要从root开始执行渲染,而不能向Vue那样,从发生变化的Vue实例向下渲染更新呢?因为Vue有响应式系统,可收集依赖关系,状态变更后影响的组件也明确,所以可以定点的渲染更新。而React没有响应式系统,加上jsx的动态性太强。如果不从root重新计算,可能很容易出现更新不完整的情况。
如果React在触发更新后,无法阻止要从root开始执行。那是不是得有一些优化策略来防止计算量过大呢?这是当然的,在React中,大概有几种类型的优化策略:
协调时的Diff算法。这是我们最老生常谈的,它的目的是为了复用DOM节点,减少DOM操作。它发生在render阶段的
beginWork过程中。bailout策略。这个不看源码的话很少有人知道。主要是为了复用fiber,让fiber跳过协调、render函数执行或子孙树遍历。它也是在
beginWork中起作用的。跳过更新。就是说React在某些优化路径下,虽然触发了更新,但不实际去执行渲染。直接跳过了此更新。有多个地方都会触发该策略。
就通过本文一次性的剖析和掌握原理。
协调时的Diff算法
Diff算法做前端的肯定都有了解。它就是为了复用DOM节点。因为DOM操作是高开销的,如果不做diff,每次都去销毁dom、重新创建dom,这样的耗时是无法接受的。
Vue和React15
在Vue和React15(栈协调器)之前的版本中,框架使用虚拟节点数组来表示某元素的children。Diff算法就是对比新旧虚拟节点数组,找出哪些节点可以复用(只需要更新属性)、哪些节点需要append或是delete。
Vue和React15都是使用的双端Diff算法:即新前(新数组的最前元素)、新后与旧前、旧后,定义了四个指针,相互一一比对,(比对的规则是有key看key,没有key看位置,同时type一定要一样),并往内部收缩指针,while循环直到前后指针相遇。这四步能解决90%以上的元素变更的情况,速度还是很快的。不过假如这四步都没匹配到,就有一个backup策略,直接在旧数组里遍历匹配。有点耗时,但一般走不到这里,除非你的列表在一次更新中就揉得乱七八糟。
双端Diff算法的代码,简单写下,以后有时间补充解释:

_renderDomWithDiff(oldChildren: VNode[], newChildren: VNode[]) {
let oldStartIdx = 0, oldEndIdx = oldChildren.length - 1;
let newStartIdx = 0, newEndIdx = newChildren.length - 1;
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
//...
if (oldChildren[oldStartIdx].key === newChildren[newStartIdx].key) {
// reuse()
oldStartIdx++;
newStartIdx++;
} else if (oldChildren[oldEndIdx].key === newChildren[newEndIdx].key) {
// reuse()
oldEndIdx--;
newEndIdx--;
} else if (oldChildren[oldStartIdx].key === newChildren[newEndIdx].key) {
// reuse()
oldStartIdx++;
newEndIdx--;
} else if (oldChildren[oldEndIdx].key === newChildren[newStartIdx].key) {
// reuse()
oldEndIdx--;
newStartIdx++;
} else {
const idxInOld = oldChildren.findIndex(
(node) => node && node.key === newChildren[newStartIdx].key
);
if (idxInOld !== -1) {
// reuse()
} else {
// append()
}
newStartIdx++;
}
}
//...
}React16
React16重构为fiber架构后,Diff算法也发生了变更。这是由于fiber是指针结构,通过return、child、sibling三个指针构成整颗树。没有了虚拟节点数组的概念。此时Diff算法就是要从旧fiber.child链表,对比新元素数组,来生成新fiber.child链表。由于链表是单向的,所以无法应用双端Diff算法。React选择了一种使用两次遍历的Diff算法。虽然效率比不上双端Diff算法,但已经是极限了。
第一次遍历
React认为更新的频率发生的会比新增、删除要高(比如改props、改text等,确实更高频)。所以第一次遍历,React会遍历新元素数组(通过render函数获得),并同时移动旧fiber.child的指针。可以复用则继续遍历。一旦发现有key不相同的。则退出第一次遍历。当然,理想情况就是全是更新,全都复用,那一次遍历就到头了。
第二次遍历
如果是理想情况,那遍历已经结束了。第二次遍历就不需要了。
如果是中途退出的,说明旧fiber.child链表和新元素数组都还有剩余,并且发生了新增和删除行为。第二次遍历就是要找出来怎么变化的。
首先,React将剩下的旧fiber.child链表按照key存到map中。这是为了快速查找,用空间换时间。
然后遍历剩下的新元素数组newChildren。接下来的逻辑很绕,可能需要自己多思考思考。记住几点:
newChildren就是我们希望dom变更成为的样子。
我们已知旧的dom,并且知道它们的位置。
遍历过程中,我们创建新fiber,并在map中查找可复用的旧fiber。我们只需要标记出,哪些新fiber对应的旧dom,需要往右移动即可。🌰例子1:
位置: 0 1 2 3
旧: a b c d
新: b c a d例如上面的例子,如果要将旧变更为新,那么b、c、d不用移动,只需要给a往右移动即可(我们先不用管移动几格)。
React使用一个lastPlacedIndex来代表最靠右的可复用的旧元素的index。遍历过程中,如果可复用的旧元素index比lastPlacedIndex大,那更新lastPlacedIndex的值即可,不用标记。如果不比lastPlacedIndex大,那这个fiber是需要标记右移的。
对比上面的例子:
- 遍历到
b=>lastPlacedIndex设置为1; - 遍历到
c=>lastPlacedIndex设置为2; - 遍历到
a=>lastPlacedIndex不变,标记a需要右移(设置fiber.effect = Placement); - 遍历到
d=>lastPlacedIndex设置为3。
代码比较复杂,感兴趣的看看源码。
那么就发散一下,🌰例子2:假如旧为abcd,新为dabc,怎么标记?答案:a、b、c都标记Placement往右移动。
可能大家会问,为什么不用知道往右移动多少步,只标记了一个
Placement。那在commit阶段是怎么正确移到目标位置的呢?
这里不具体详细讲了。简单说下:commit阶段对于标记了Placement的fiber会找它的右侧下一个稳定的(没有Placement标记)兄弟fiber(getHostSibling方法)。找到后,将fiber对应的dom插入到兄弟dom的前面。
比如例子1,fibera的下一个稳定fiber是d,那就是旧doma需要插入到旧domd前面。对于例子2,fibera没有下一个稳定的fiber,插入doma到最后,同理插入domb到最后,插入domc到最后。新dom变成了dabc。
总结:Diff算法
- Vue和React15之前,Diff算法使用的是双端Diff算法。效率很高。
- React16之后,由于React改为了fiber架构,fiber的链表遍历机制导致无法使用双端Diff算法,改为了二次遍历的算法,性能有所降低,但仍然很高效。
bailout策略
Diff算法是为了协调时,找出DOM变更并标记。即使是最理想的情况下,它的时间复杂度也有O(N)(N是newChildren的长度)。那bailout策略就是为了:
- 让fiber跳过协调步骤;
- 跳过fiber对应的组件的render函数,也就是我们常说的组件渲染;
- 将fiber的子孙树,全跳过render阶段和commit阶段,停止往下遍历。
我们区分一下优化等级:
- 仅跳过协调:🌟Level1
- 跳过渲染+协调:🌟Level2
- 跳过协调+子孙树:🌟Level3
- 跳过渲染+协调+子孙树:🌟Level4
主要的代码都在beginWork里,其中最重要的字段就是didReceiveUpdate,代表当前fiber是否需要更新。它是个全局变量。多个地方都有设置和读取。它会控制最后的bailout策略优化的程度。
首先我们先简化一下beginWork的代码,只保留关键部分,方便理解。
// 每个fiber,都会作为一个工作单元,执行beginWork
function beginWork(current, workInProgress) {
if (current !== null) { // 更新时
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (oldProps !== newProps || hasLegacyContextChanged()) {
// props对象不全等,或者旧版Context有变化,标记有更新
didReceiveUpdate = true;
} else if (!includesSomeLane(renderLanes, workInProgress.lanes)) {
// 当前fiber的lane不在本次更新的lane里。代表该fiber要么没有更新,要么更新优先级不够
didReceiveUpdate = false;
switch (workInProgress.tag) { /* 符合bailout策略,根据fiber类型做一些收尾工作 */ }
// 执行bailout优化
return bailoutOnAlreadyFinishedWork(current, workInProgress);
} else {
// props全等,但是有更新。先置为false。如果state或context变化,后续会置为true
didReceiveUpdate = false;
}
} else { /* mount时 */}
// 如果前面没有bailout,根据fiber类型执行对应的工作。当然,里面还有机会bailout。
switch (workInProgress.tag) {
case FunctionComponent:
return updateFunctionComponent(current, workInProgress);
case ClassComponent:
return updateClassComponent(current, workInProgress);
case SimpleMemoComponent:
return updateSimpleMemoComponent(current, workInProgress);
//...
}
}可以看到,beginWork函数一开始,会给予当前fiber首次bailout的机会。我们先看条件判断。
props属性全等
首先判断oldProps !== newProps || hasLegacyContextChanged()。其中hasLegacyContextChanged我们可以不用管,这是React15之前的旧版本context api,用来判断有没有context变化,这里是为了兼容。我们只看oldProps !== newProps,它代表新旧fiber的props对象是否全等。如果不全等,那就暂时认为有更新,设置didReceiveUpdate为true。什么情况下新旧fiber的props全等呢?
这就要看新的fiber是怎么被创建出来的。新的fiber最终都是通过createWorkInProgress方法创建的,它接受两个参数:旧fibercurrent和props属性pendingProps。全局搜索一下这个函数的调用,其实发现使用到的地方不多。其中,只有一个地方它会使用旧fiber.pendingProps。
这个地方就是cloneChildFibers方法。这个方法作用是,对于当前fiber,构建自己的fiber children。属性都是从旧fiber children直接拷贝过来的,自然props对象也是。
而除了cloneChildFibers方法,其他地方调用createWorkInProgress方法都类似于createWorkInProgress(current, element.props)。其中element.props是从React.createElement方法创建的Element对象的props。我们看源码能看到,每次createElement方法都会创建一个新对象作为props:const props = {}。
也就是说,只有当父级调用cloneChildFibers拷贝生成子fiber时,轮到子fiber执行beginWork。才会进入props全等的条件。这个条件相当苛刻。
判断当前fiber的lane
先抛开何时执行cloneChildFibers,继续看怎么进入首次bailout。假如props全等,那会继续判断!includesSomeLane(renderLanes, workInProgress.lanes)。
其中renderLanes是指本次更新渲染它允许的lanes值。workInProgress.lanes就是当前fiber的lanes值。includesSomeLane就是个位运算,判断两者是否有相交。所以这里的条件就是判断当前fiber是否没有更新或者lane优先级不够,不需要更新。
如果不需要更新,那就走进了首次bailout。执行bailoutOnAlreadyFinishedWork。
bailoutOnAlreadyFinishedWork
bailoutOnAlreadyFinishedWork方法就是优化,看一下方法的代码:
function bailoutOnAlreadyFinishedWork(current, workInProgress) {
// 判断它的子孙是否有优先级足够的更新
if (!includesSomeLane(renderLanes, workInProgress.childLanes)) {
// 如果子孙也没有,那直接返回null,子孙树就直接被跳过后续步骤了
return null;
} else {
// 如果当前fiber没有优先级足够的更新,而子孙树下面有
// 跳过协调过程,直接拷贝children。
cloneChildFibers(current, workInProgress);
return workInProgress.child;
}
}首先判断workInProgress.childLanes是否在本次更新的优先级范围内。fiber.childLanes是它的子孙fiber树里,子孙fiber的lane叠加的结果。举例说明:
a
/ \
b c
/ \ \
d e f如上的fiber树。如果fibere上触发了更新。则e.lanes会被设置一个优先级。那它的所有parent,即b和a,都会被设置childLanes,合并的方法是mergeLanes,因为可能parent的childLanes不为0。childLanes被设置的时机我之前讲过,一个是markUpdateLaneFromFiberToRoot时,一个是Provider发现状态变更时。不再重复说,我们只需要知道childLanes不为0,代表它的子孙树有更新。
回到上面,!includesSomeLane(renderLanes, workInProgress.childLanes)为true,代表子孙树没有更新或优先级不够。走到这里,说明当前fiberprops全等、自己没更新、子孙也没更新。React对该fiber选择了最高等级的优化,即🌟Level4:什么事也不做,并返回null,代表它的子孙后代都不用往下进行了。
但是假如为false,代表子孙树有更新,自己没更新。那自己可以跳过协调过程,直接copy,然后copy之后,返回自己的child,作为下一个工作单元。对于首次bailout,那它就是🌟Level2。
总结:首次bailout
也正好接到前面,可以看到copy的方法,正是我们刚刚讲到的cloneChildFibers方法。这说明了什么呢?总结一下:
某个fiber想要进入首次bailout,那它的父级fiber就必须进入bailout策略。且自己不能有对应优先级的更新。
可能大家看到这里都会觉得很绕,其实我们可以试着这么理解:bailout代表了fiber没有更新,也不需要协调。如果父fiber没有bailout,那子fiber肯定不能直接在首次就执行bailout优化。至少要执行渲染才知道该不该优化呀。
继续往下讲,如果走不到首次优化,beginWork会继续往下执行,会根据fiber的组件类型,执行具体的函数。
函数组件
对于函数组件,会执行updateFunctionComponent方法。去掉DEV之类的代码:
function updateFunctionComponent(current, workInProgress) {
//...
// 调用render函数
let nextChildren = renderWithHooks(current, workInProgress);
// 第二次bailout的机会
if (!didReceiveUpdate) {
//...
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
// 不走bailout,进入协调
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
return workInProgress.child;
}可以看到updateFunctionComponent方法内,先执行组件的render函数。对于函数组件,那就是函数自身。然后会根据didReceiveUpdate这个全局变量。给予第二次bailout的机会(🌟Level1或🌟Level3)。如果还没进入bailout,那对不起,没有机会了,执行协调算法吧。
可能有人会问了,前面beginWork里确实根据条件设置了didReceiveUpdate变量。这个函数里没有啊,为什么不直接在前面判断呢?重点就在于didReceiveUpdate是个全局变量。我们看renderWithHooks这个函数:
function renderWithHooks(current, workInProgress) {
//...
let Component = workInProgress.type
let children = Component(props, secondArg);
//...
}大部分代码和我们要讲的无关,去掉了。其实很清晰,就是直接执行函数组件的函数本身。这个方法也没有修改didReceiveUpdate全局变量,我们的函数组件里都是我们自己写的代码,也不可能会手动去修改这个全局变量啊。那现在到底哪里设置了呢?我觉得大家应该能猜出来了,那就是Hooks。我们不会在函数组件里直接修改didReceiveUpdate全局变量,但是我们经常调用Hooks。会不会是Hooks内部修改的呢?
我们检查ReactFiberHooks.js,在updateReducer方法中,看到调用了markWorkInProgressReceivedUpdate方法。而markWorkInProgressReceivedUpdate方法就一行:didReceiveUpdate = true;。
我们知道updateReducer方法,就是函数组件的useState和useReducer这两个Hooks在React内部调用的。它会根据Update链表和优先级来更新state。也因此,我们在函数组件内总是能获取到最新的state。当然这些不是重点,重点是这句:
function updateReducer() {
// ...
let newState = null
let update = first
do {
// 根据Update和lane来更新state
} while (update !== null)
// 重点在这里!
if (!is(newState, hook.memoizedState)) {
markWorkInProgressReceivedUpdate();
}
//...
return [hook.memoizedState, dispatch];
}如果hook计算后的newState和旧的state通过Object.is对比是不一样的。那就标记fiber有更新。那就不会进入第二次bailout。
也就是说,state发生改变一定不走bailout,会执行渲染和协调。未发生改变,就有可能走bailout。它期望优化的是这种情况:
function FuncComp() {
const [count, setCount] = useState(0)
return <button onClick={() => {
setCount(1)
setCount(0)
}}>按钮</button>
}state发生了多次改变,但最终state还是和原来一样。这种情况,通过bailout策略。让fiber跳过了协调过程。
React.memo
类组件具有类似于函数组件的优化,就不说了。我们现在说一下经常用来做性能优化的api:React.memo。
我们知道,React.memo会包装我们传入的组件,如果我们传入的是函数组件,fiber.tag将会是SimpleMemoComponent。在beginWork里,它最终会调用updateSimpleMemoComponent方法:
function updateSimpleMemoComponent(current, workInProgress) {
//...
if (current !== null) {
// 浅比较props对象
if (shallowEqual(prevProps, nextProps)) {
didReceiveUpdate = false;
// 如果当前fiber没有更新,bailout
if (!includesSomeLane(renderLanes, workInProgress.lanes)) {
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
}
}
return updateFunctionComponent(current, workInProgress)
}代码也不复杂。浅比较props对象,如果通过,didReceiveUpdate置为false。如果当前fiber无更新,则走bailout优化(🌟Level2或🌟Level4)。不通过或者fiber有更新,则继续走上面updateFunctionComponent的逻辑。
这里有一个很重要的知识点,就是
React.memo默认使用的是浅比较props对象。这样的话,如果我们使用对象或函数作为props传递给子组件的话。那需要使用useMemo和useCallback对它们进行封装。否则浅比较是不会通过的。
总结:bailout策略
bailout策略的优化路径和对应的代码逻辑,到这里就全部列举完了。此刻,我们可以总结一下bailout策略的规则:
首先,我们知道了,一个fiber进入了bailout策略,它就不需要再协调children了。它需要满足:这个fiber的props、state都没有发生变化。(当然还有context,不过context是否变化已经体现在lane值上了)。
如果父fiber进入了bailout,那子fiber的props一定未变化。接着只需要检查fiber的state是否有变化。
判断fiber的state是否有变化,我们首先判断是否有更新(通过lane值)。即使有更新,也要判断state是否真的发生了变化。
props和state都未变,则可以执行bailout。有一项不满足,就需要老老实实执行协调。
可推出,bailout具有一定的传染性。父fiber走了bailout,子fiber也会走,除非子fiber有更新。一旦某fiber不走bailout,子孙都不走,除非子孙使用
React.memo。
画一个流程图,让逻辑更加清晰一些。
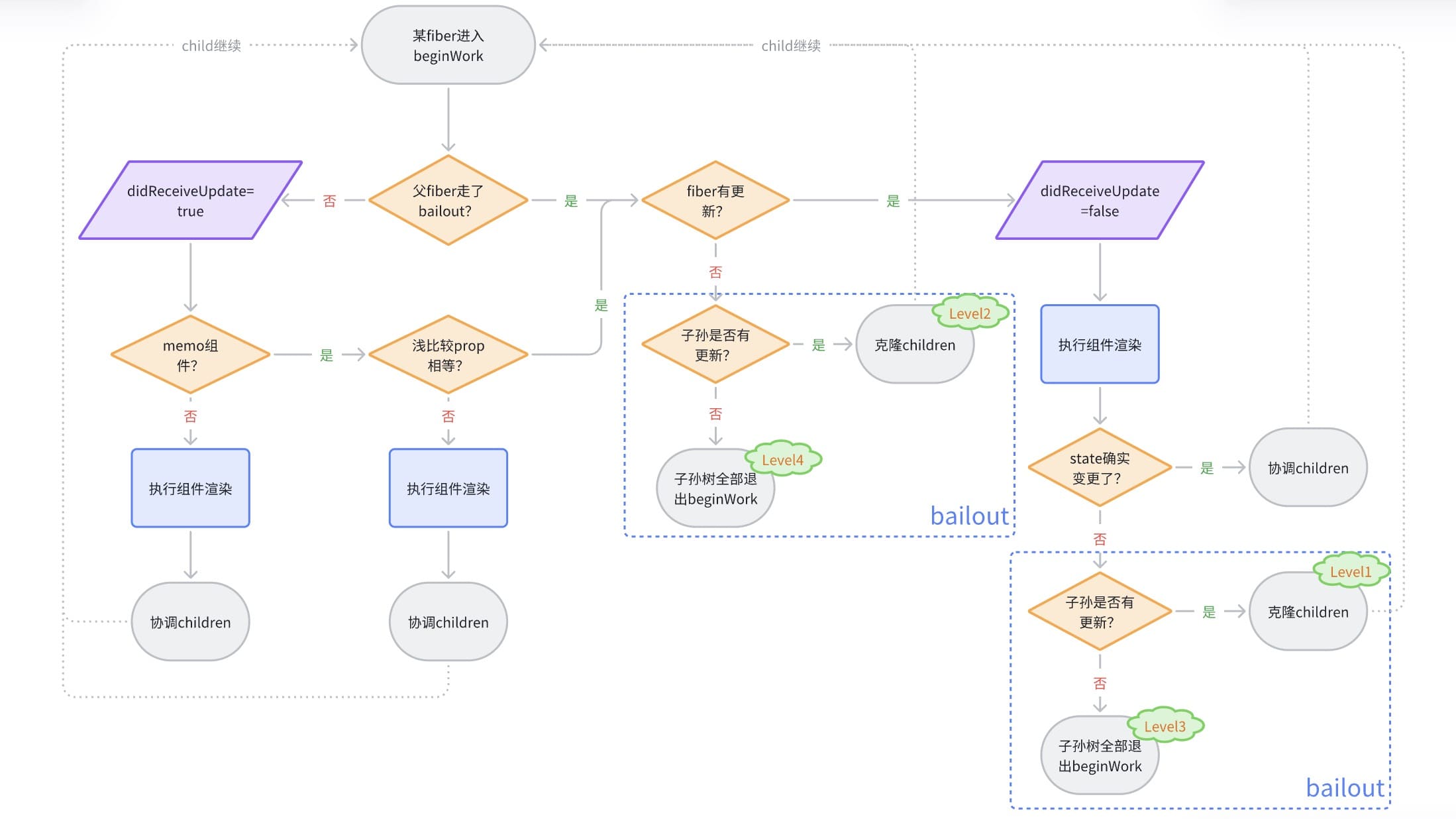
再总结一下,想要跳过组件渲染的规则是什么:
父fiber进入了bailout,fiber才会有首次bailout的机会。首次bailout会跳过组件渲染。
如果fiber使用
React.memo包裹并浅比较props相等。那它和父fiber进入了bailout是一个效果。所以说
React.memo给了fiber第二次跳过组件渲染的机会。这次再不满足,组件渲染就一定会执行。
至此,我们甚至可以从原理层解释一些React中的现象:
一个组件的state发生了变化,触发了更新。其子孙组件如果没被
React.memo包裹,都会重新渲染(当然也会重新协调)。React.memo包裹的组件,如果props浅比较不相等,或state发生了变更,也会重新渲染(+重新协调)。
展开说一句。我们推出来bailout具有一定的传染性。React每次更新都是从rootFiber开始的,这是不是代表每次更新,从根开始的所有组件都会执行一次渲染?当然不是这样。那React是怎么处理的呢?
首先,我们知道React不可能给rootFiber套个React.memo。事实上,我们debug一下就知道。rootFiber的pendingProps和memoizedProps始终是null。所以从rootFiber开始会进入bailout,其子孙组件也会进入到bailout,而且是首次bailout。组件渲染函数不会执行。直到遍历到触发更新的更新源。
跳过更新
bailout是React针对fiber树渲染工作所做的优化,它会跳过很多不必要的渲染工作。在这之上,React还有更直接的优化手段。那就是跳过更新:组件触发了更新,但最终并不唤起渲染流程。我们看一下有哪些手段。
批处理
对于函数组件,触发更新的方法是useState的dispatch函数。我们也知道,并不是每一次调用dispatch都会触发更新。这是由于React有批处理的能力。简单来说:
function FuncComp() {
const [count, setCount] = useState(0);
const [flag, setFlag] = useState(false);
return <button onClick={() => {
setCount((c) => c + 1);
setFlag(f => !f);
}}>按钮</button>
}上述代码,在事件处理器中,我们调用setCount((c) => c + 1)改变状态,会触发一次更新,React紧接着会调度一次渲染。但我们调用setFlag(f => !f)时,React不会再调度一次渲染。这正是由于React批处理的存在。这里被批处理的主要代码其实很简单:
function ensureRootIsScheduled(root, currentTime) {
// ...
// 获取本次更新的lanes
var nextLanes = getNextLanes(root, workInProgressRootRenderLanes);
var newCallbackPriority = getHighestPriorityLane(nextLanes);
var existingCallbackPriority = root.callbackPriority;
// 已调度更新的优先级 === 本次更新优先级,不需要再发起一次调度
if (existingCallbackPriority === newCallbackPriority) {
return;
}
// 继续调度更新
//...
}可以看到,如果已经有相同优先级的更新,就会跳过本次触发的更新。想要更详细的了解批处理的原理,可以参考我之前的文章【谈一谈React18的批处理】,不再赘述。
eagerState
设想一下,如下场景:
function FuncComp() {
const [count, setCount] = useState(0);
return <button onClick={() => {
setCount((c) => c);
}}>按钮</button>
}问:点击按钮后,React会执行一次重新渲染吗?
当然不会了,因为点击按钮后,state不会发生任何改变,根本没必要重新渲染。不信的同学可以写个demo试试看。
那React是怎么处理这类情况的呢,是否跟我们之前bailout策略讲的那个例子是一样的原因呢?
不一样,之前bailout的那个例子,是state多次变更。它触发了React的重新渲染,并在执行组件渲染后,发现state最终并未改变,于是进入了bailout流程。而这次,其实可以更提前些,因为我们明确知道它不会改变state。所以干脆可以不触发重新渲染。提前到什么时机呢?看来只能在dispatch函数里面了:
// ReactFiberHooks.js
function dispatchAction(fiber, queue, action) {
//...
// reducer
const lastRenderedReducer = queue.lastRenderedReducer;
const currentState = queue.lastRenderedState;
const eagerState = lastRenderedReducer(currentState, action);
// 如果eagerState和之前的state一样,直接退出
if (is(eagerState, currentState)) {
return;
}
//...
// 发起更新
scheduleUpdateOnFiber(fiber, lane, eventTime);
}调用state的dispatch方法,React底层会调用dispatchAction方法。对于useState和useReducer来说它们的代码是一致的,因为useState也可以使用一个基础的reducer函数来dispatch:
function basicStateReducer(state, action) {
return typeof action === 'function' ? action(state) : action;
}再看dispatchAction方法。其实它就是对当前action做了一个计算,得到了eagerState。然后再使用Object.is对比eagerState与之前的state是否一样。如果一样,直接退出,不再发起渲染。
总结:跳过更新
React会通过批处理和eagerState手段来让某些更新,最终并不引起重新渲染。
- 批处理就是将多次更新合并,只触发一次重新渲染的能力。
- eagerState就是优化,state被执行dispatch方法,但是值未发生变化的场景。它会直接return,不触发渲染。
对比Vue框架?
我们都知道,React的能力正在变得越来越强大。fiber架构、时间切片、优先级调度、Hooks、jsx、SSR、RSC、流式渲染...。在提升能力、灵活性的同时,它的代价就是架构的复杂度提升,并由此带来基础性能的损耗:
fiber架构复杂性太高,代码量巨大,基础性能较React15有所下降。
fiber的链表式遍历导致Diff算法的协调效率下降。
jsx的灵活性,也导致React始终需要通过完整计算,才能保证结果的正确性。
所以,React不得不在框架底层做了很多的性能优化。同时暴露部分性能优化的API,期望开发者通过这些API来手动提升性能。但实际上,对于开发者来说,这无疑增加了编码的心智负担。并且不同熟练度的开发者,对React应用的性能优化程度也相差甚远。这么来说,React确实是有不少问题存在的。
我们观察一下隔壁家的Vue。它好像更显得亲民一些:
Vue没有异步可中断能力,不需要类似的fiber架构和时间切片。架构复杂度并没有那么高,运行时只占React的一半以下。基础性能理论上高一些。
Vue使用高效的双端Diff算法,同时Vue使用模版语法描述UI,所以静态分析完全可行。去掉静态节点(静态节点可能会占到节点数的80%以上),diff效率大大提升。
Vue包含一个响应式系统,可以响应式追踪和收集依赖。因此Vue可以做到,状态的变化只引起特定组件的重新渲染,更精准。这种局部更新的效率比React全局更新的效率高。并且,它都是Vue从框架层面实现的,开发者没有任何心智负担。
哇,如此看来,Vue岂不是更完美吗,那以后我们都去使用Vue开发应用好了?
哈哈,当然也不是。React为什么做时间切片,不就是为了解决CPU密集的场景嘛?比如可视化场景,这样的应用计算量大、动画还特别多。没有时间切片的话,一旦运算超过16ms,就会卡一帧,超得越多,卡得越多。动画会显得很不流畅。另外,确实React的如此设计带来了基础性能的损耗,但是这个损耗对用户体验是否也带来了影响?可能并没有想象的那么大,时间切片机制更模糊化了这个影响。
另外的,Vue的响应式系统我认为是把双刃剑。它会导致项目的数据劫持过多,也会导致性能损耗。当然,内存也会产生额外的开销。
总而言之,Vue和React单从性能角度考虑的话,其实各有千秋。具体选型的时候使用哪种技术,还是要综合考虑使用场景、需要的能力、团队的技术栈、生态等等。